We introduce CreativityBench, a comprehensive benchmark for evaluating creative intelligence in large language models (LLMs) through the lens of affordance-based creative tool use. While recent progress in LLMs has demonstrated strong analytical reasoning and practical task execution, their ability to generate novel yet physically grounded solutions under constraints remains largely underexplored.
CreativityBench addresses this gap by focusing on a core aspect of human creativity: the ability to repurpose objects based on their underlying affordances, reasoning about how an object’s parts, attributes, and physical properties enable unconventional but plausible uses. Rather than relying on canonical tool usage, the benchmark evaluates whether models can identify non-obvious, constraint-satisfying solutions grounded in physical reality.
CreativityBench is more than a benchmark, but it is a structured and scalable evaluation framework for creative reasoning, designed to uncover fundamental limitations in current models and guide future progress toward more flexible, adaptive intelligence.
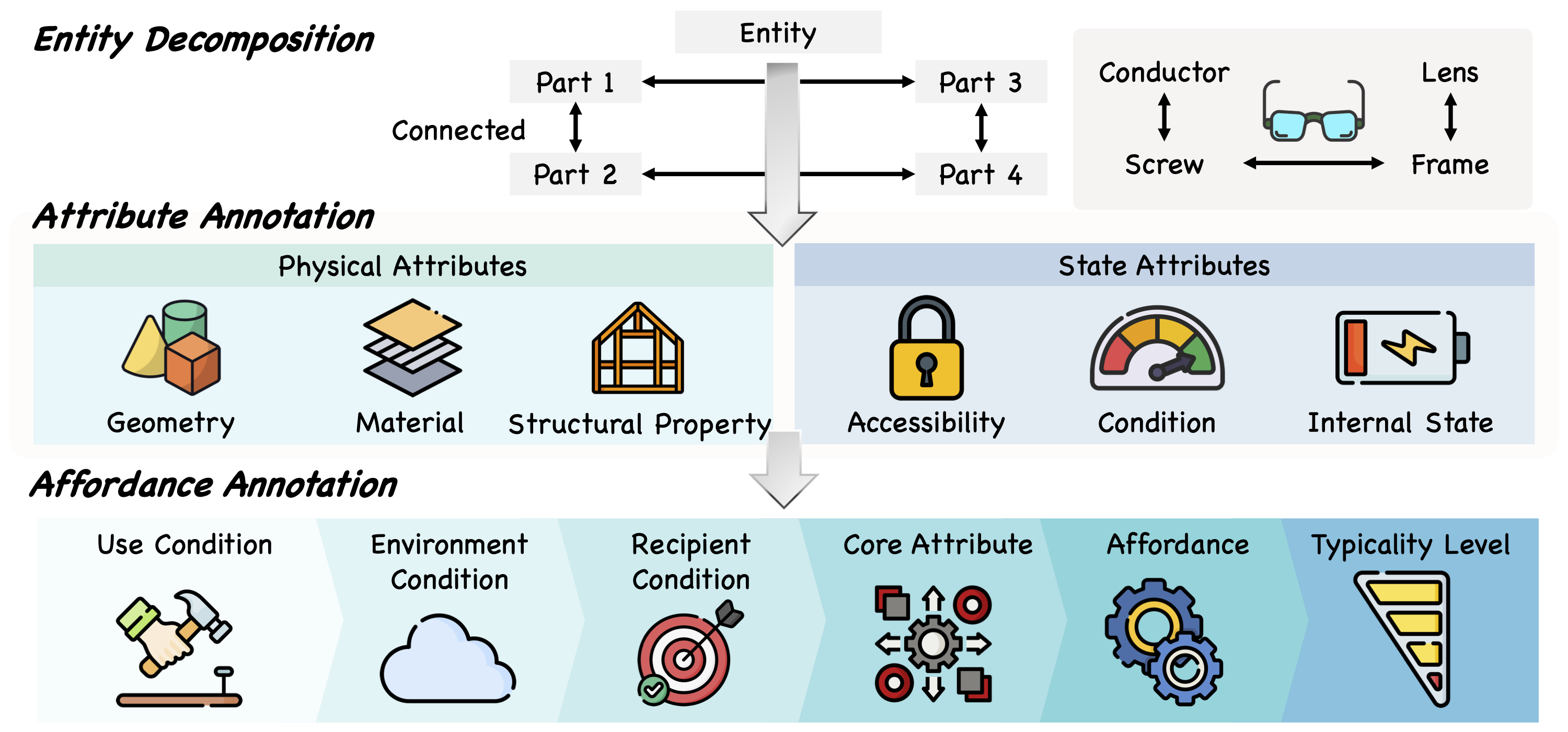
We construct a large-scale, structured affordance knowledge base (KB) containing 4K entities and 150K+ affordance annotations, explicitly linking objects to their parts, attributes, and actionable uses. This KB enables grounded reasoning by anchoring model decisions in fine-grained physical properties, rather than surface-level semantic associations.
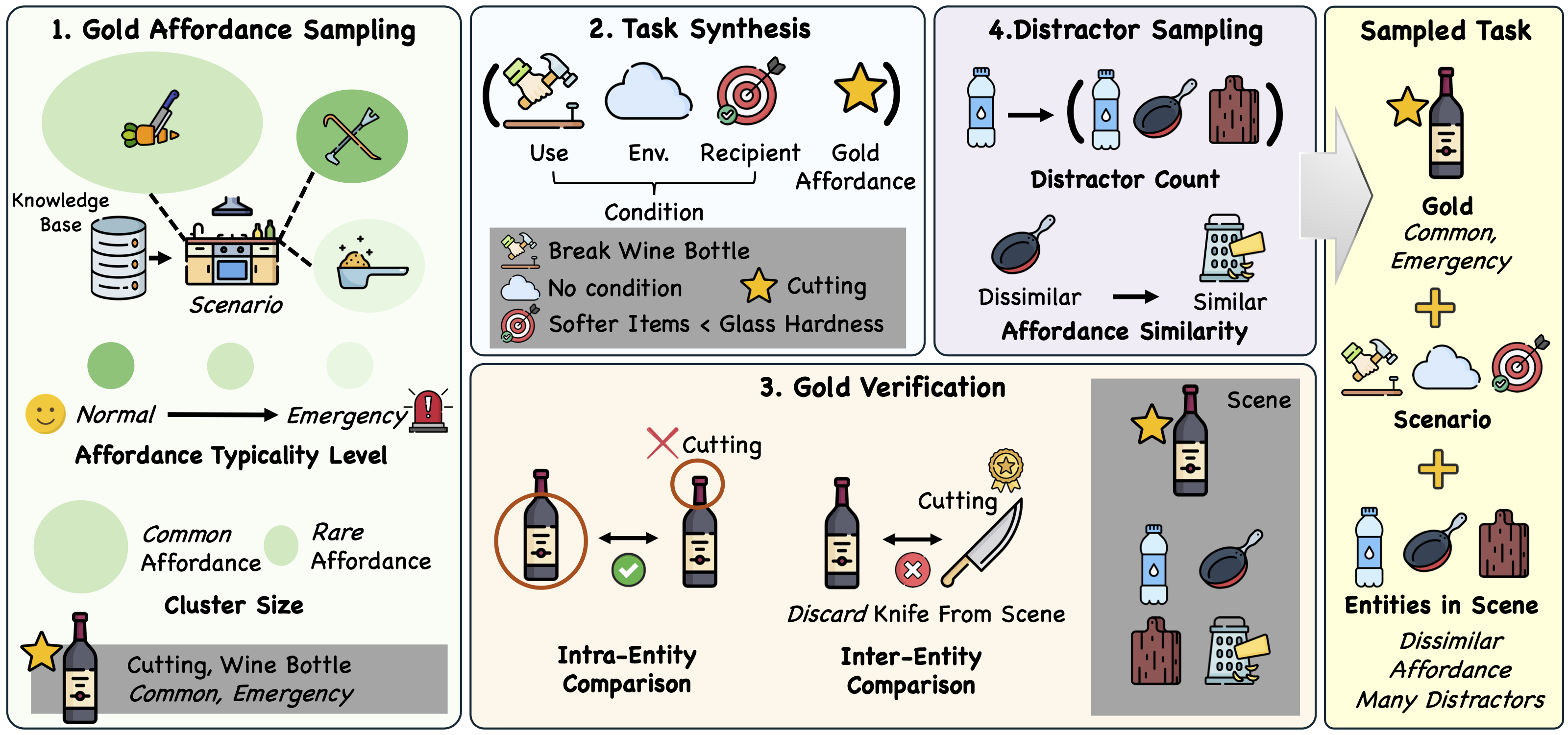
Using our affordance KB, we generate 14K diverse tasks that require models to identify non-obvious yet physically plausible solutions under constraints. Each task is constructed to go beyond object-level plausibility, requiring models to reason about how affordances emerge from structure and how they can be recombined to achieve a goal.
From the metric perspective, current models are better at choosing plausible tools at the entity level but struggle to produce fully correct, physically grounded tool use. Model reasoning is often plausible but fails to account for all conditions required for successful execution. From the model perspective, there is a clear split between creative affordance discovery and grounded reasoning quality. Improvements from model scaling alone quickly saturate, indicating that stronger performance requires advances in grounded affordance reasoning rather than size alone.
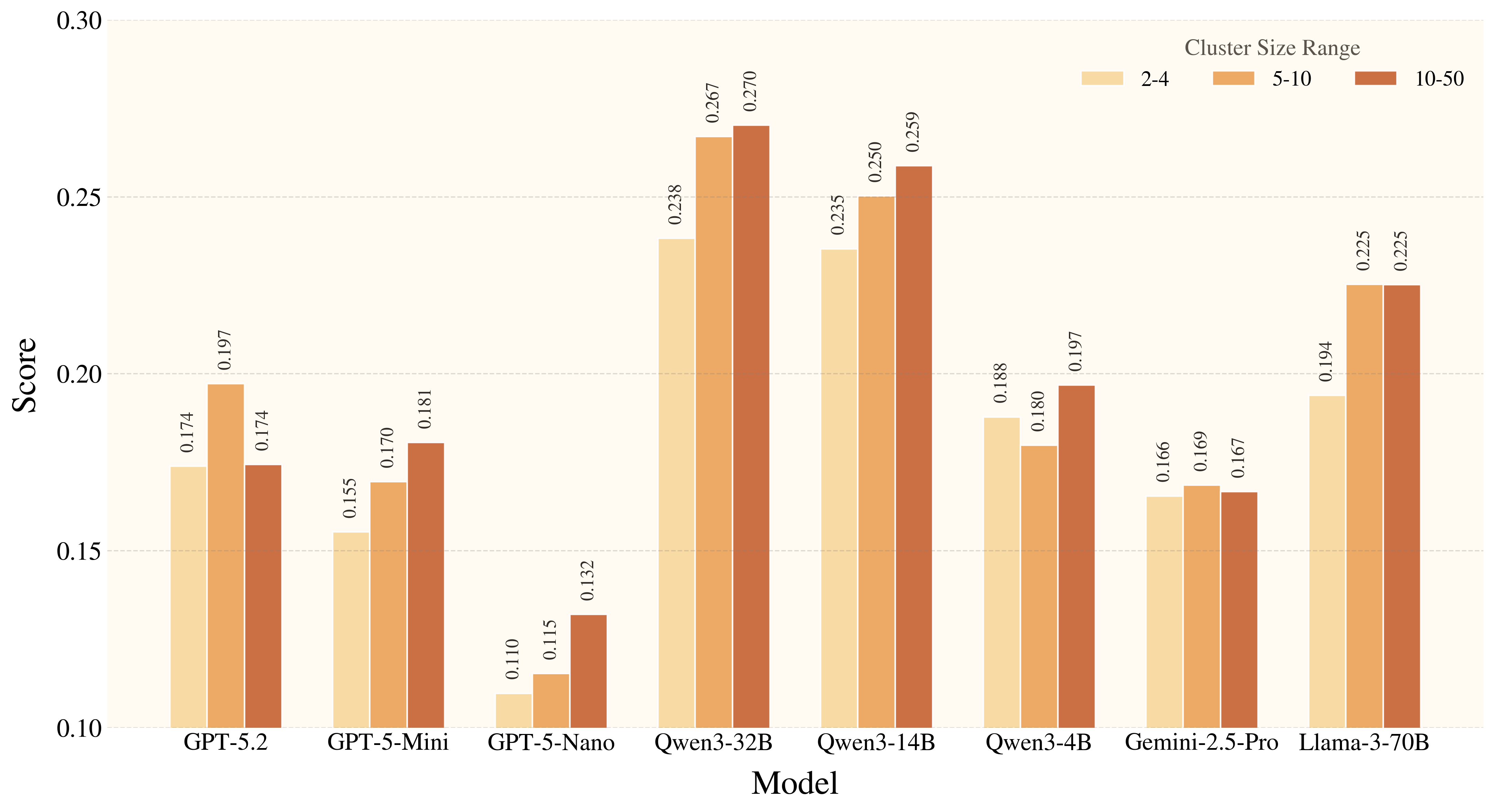
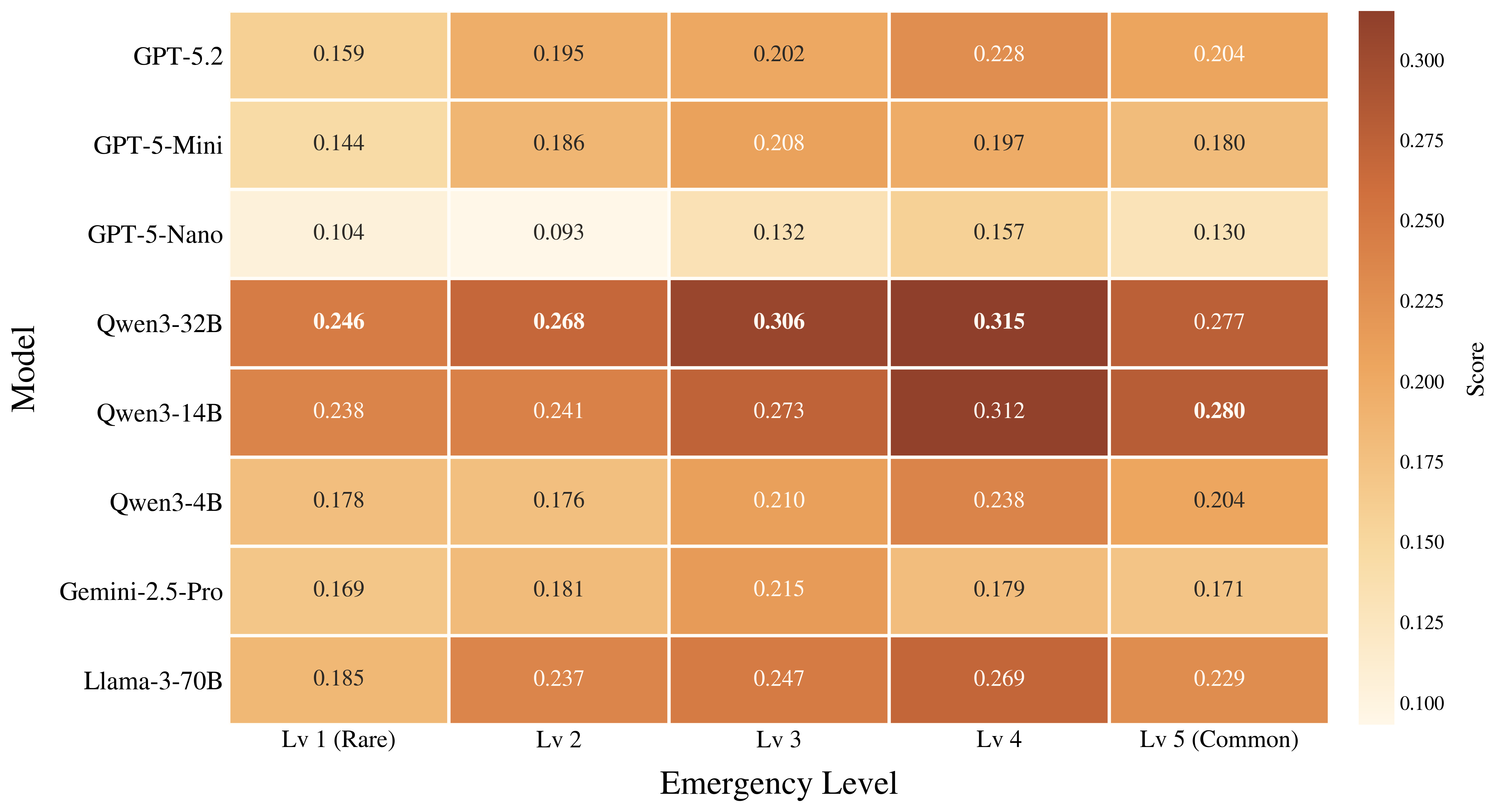
Figure 4. Model performance drops most clearly on rare, long-tail affordances, showing that commonality remains a major driver of success in grounded creative tool use.
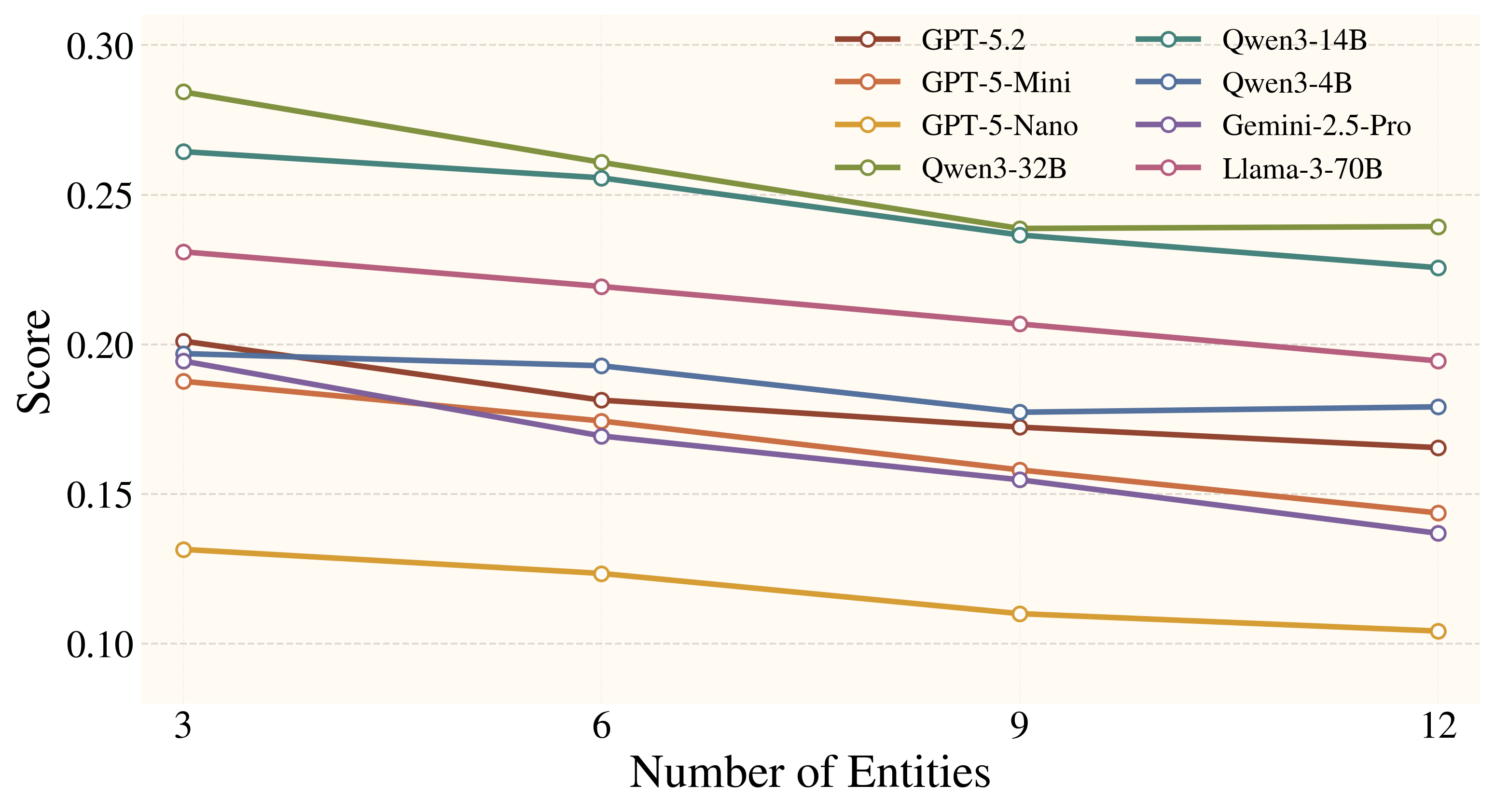
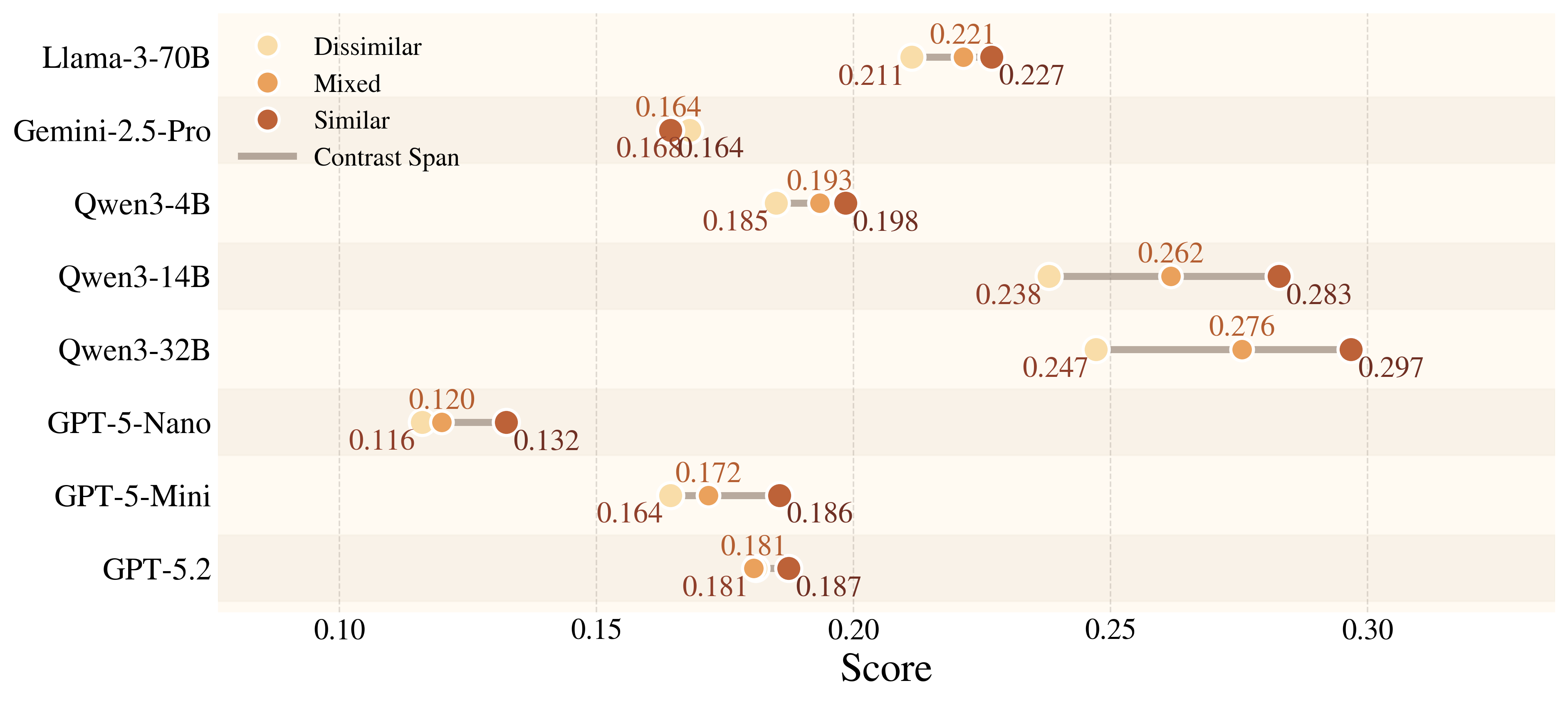
Figure 5. Both the quantity and type of distractors influence model performance. While larger candidate sets consistently increase difficulty, distractors that share similar affordances with the gold object can sometimes help highlight the relevant reasoning space, partially offsetting the distraction effect.
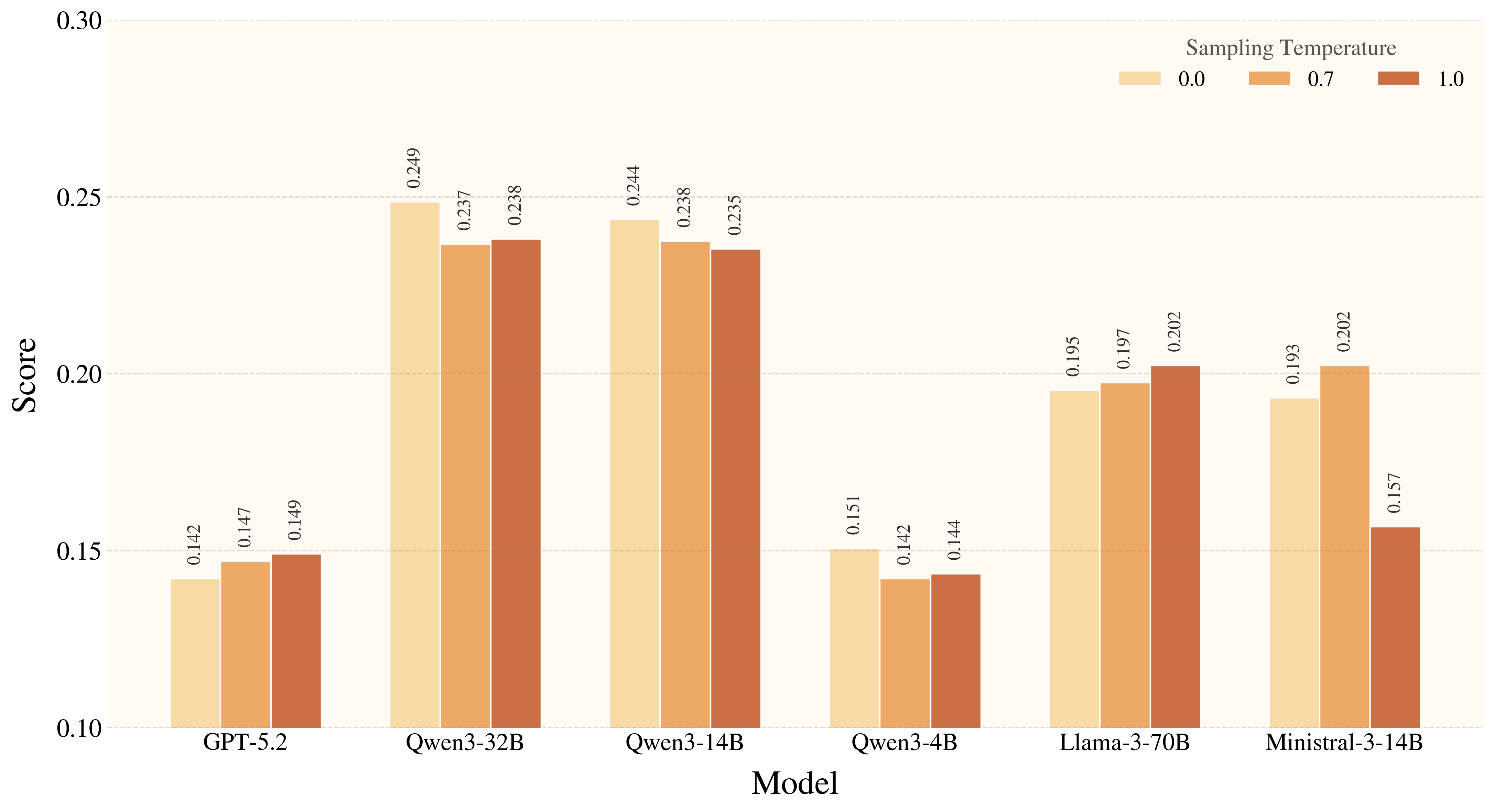
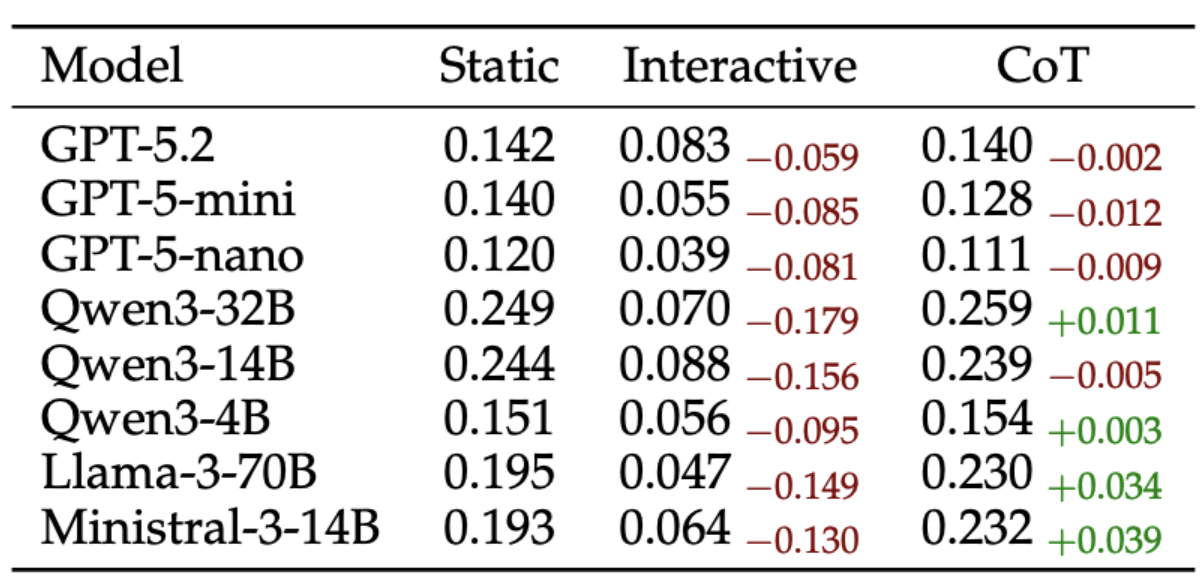
Figure 6. Increasing sampling temperature does not reliably improve creative tool use. For smaller models in particular, higher temperatures tend to increase hallucinated entities and parts rather than produce more effective affordance exploration, suggesting that this benchmark rewards grounded constraint satisfaction rather than open-ended generative diversity.
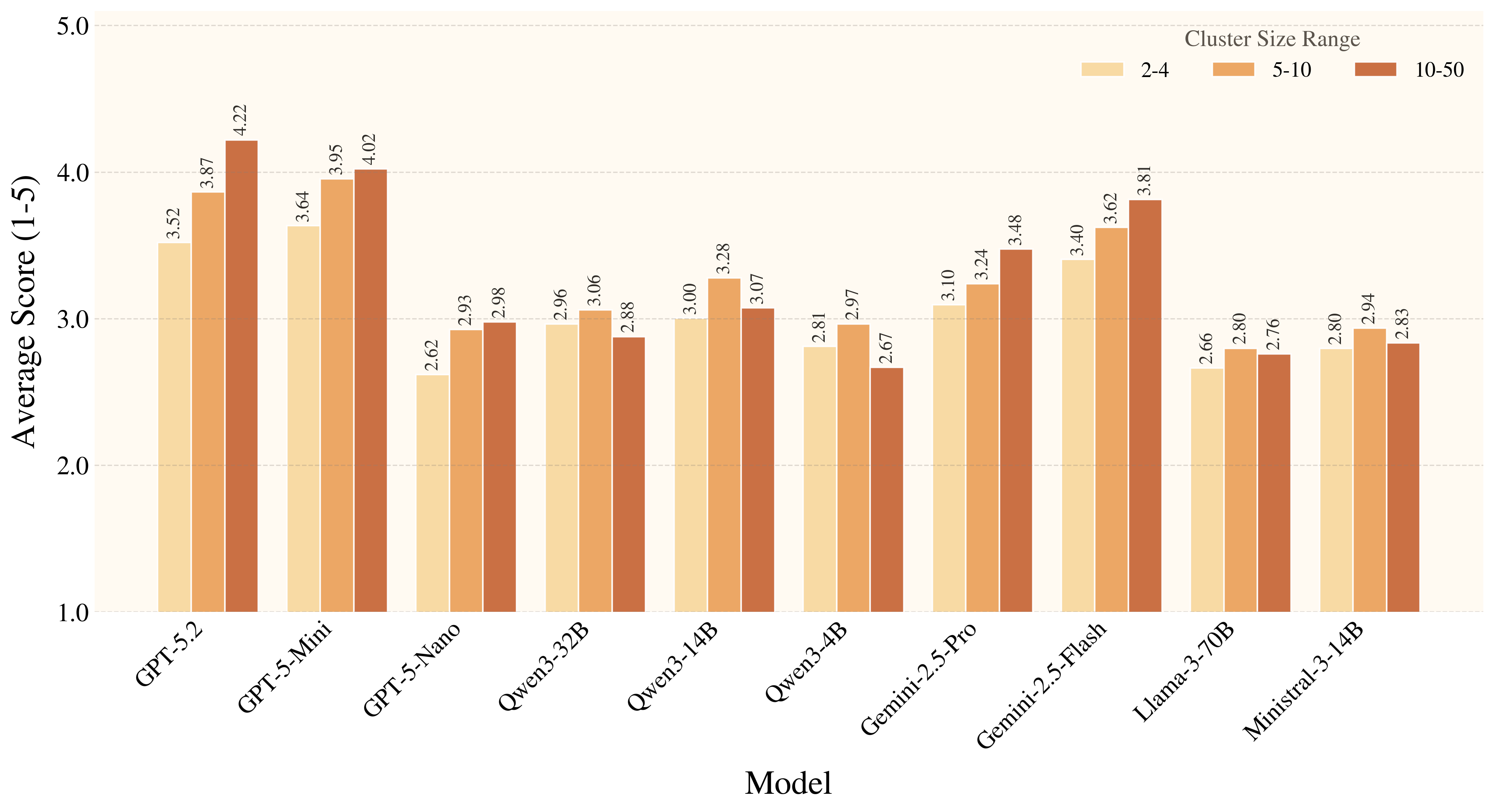
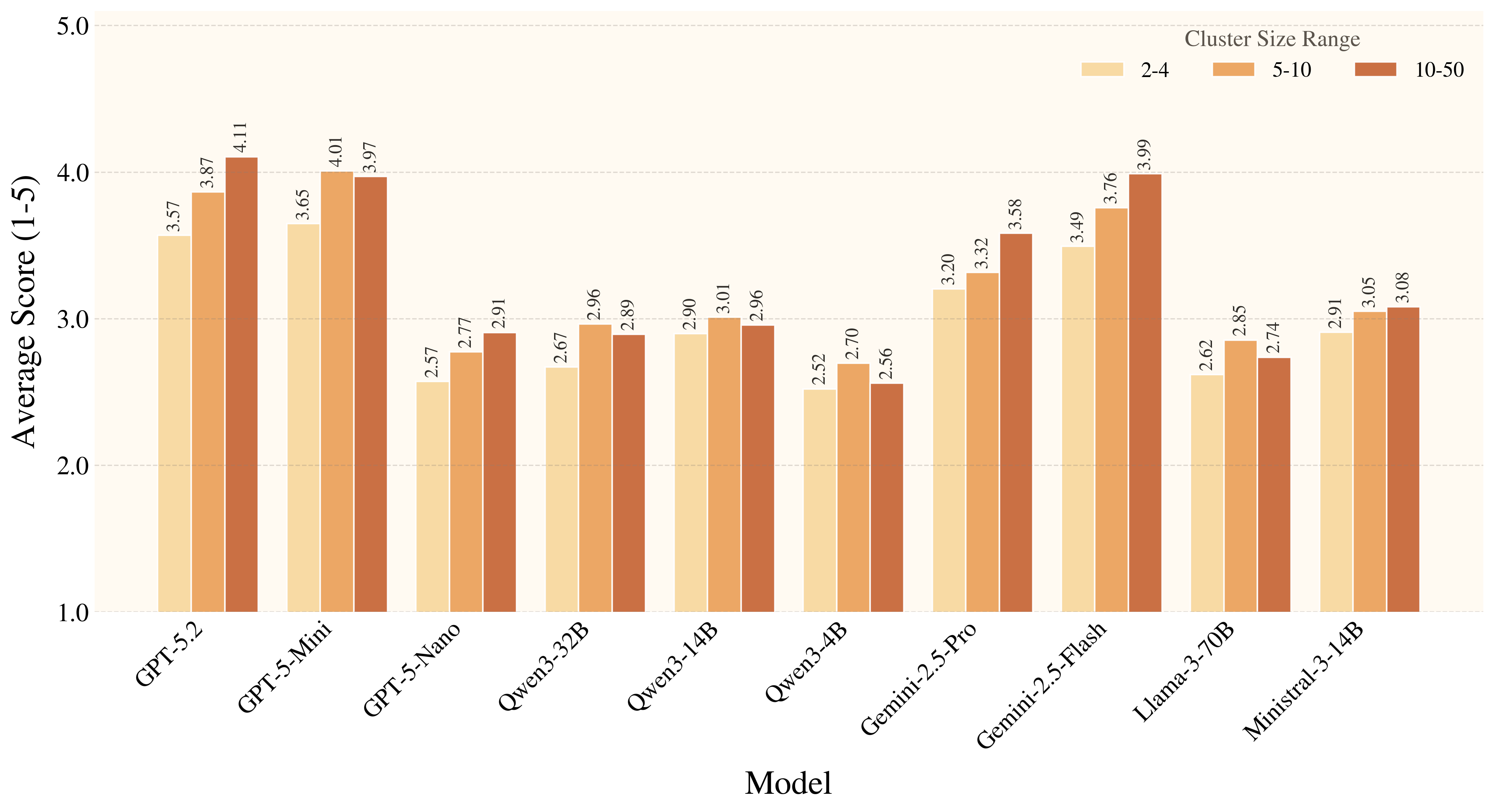
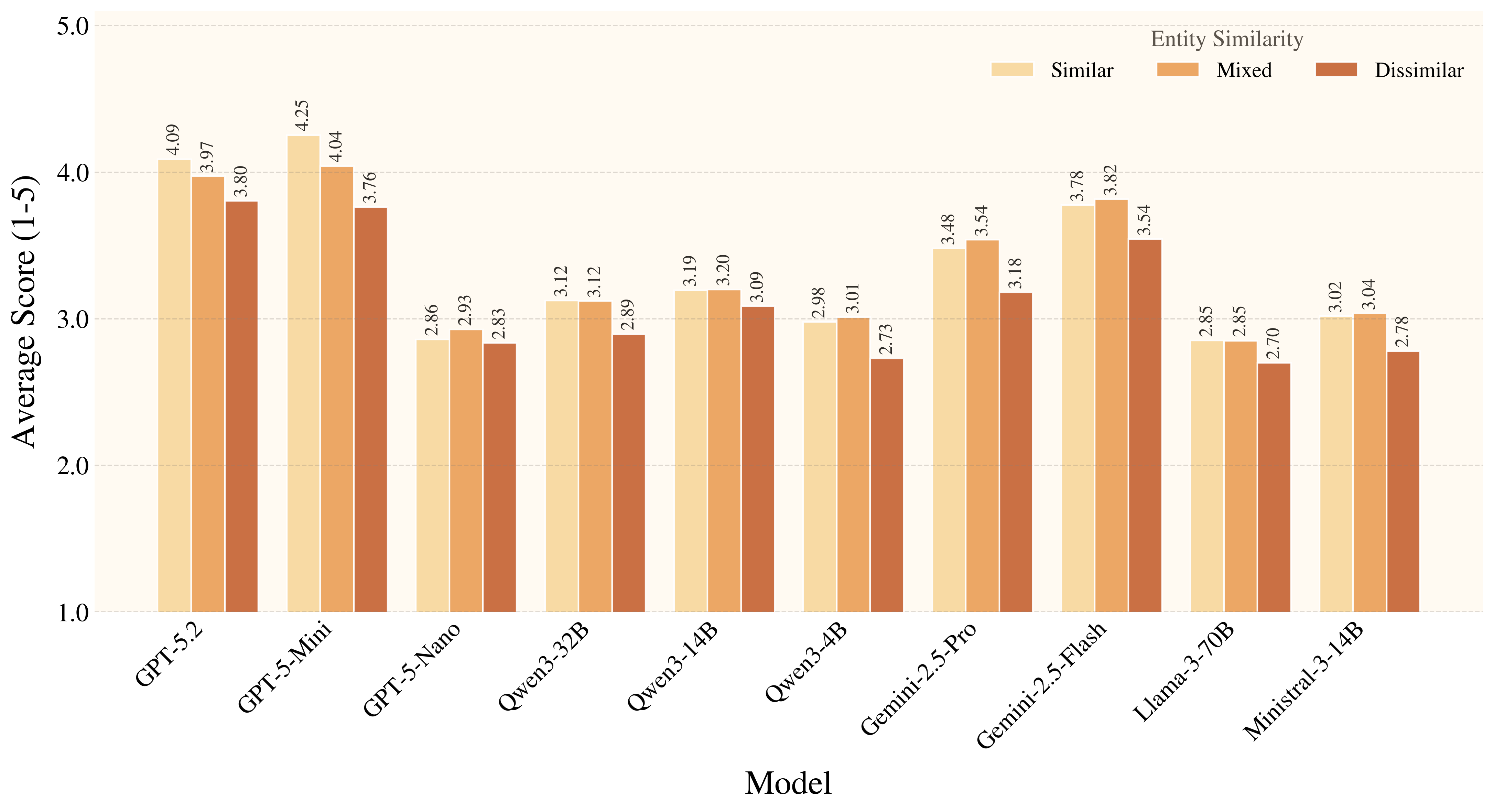
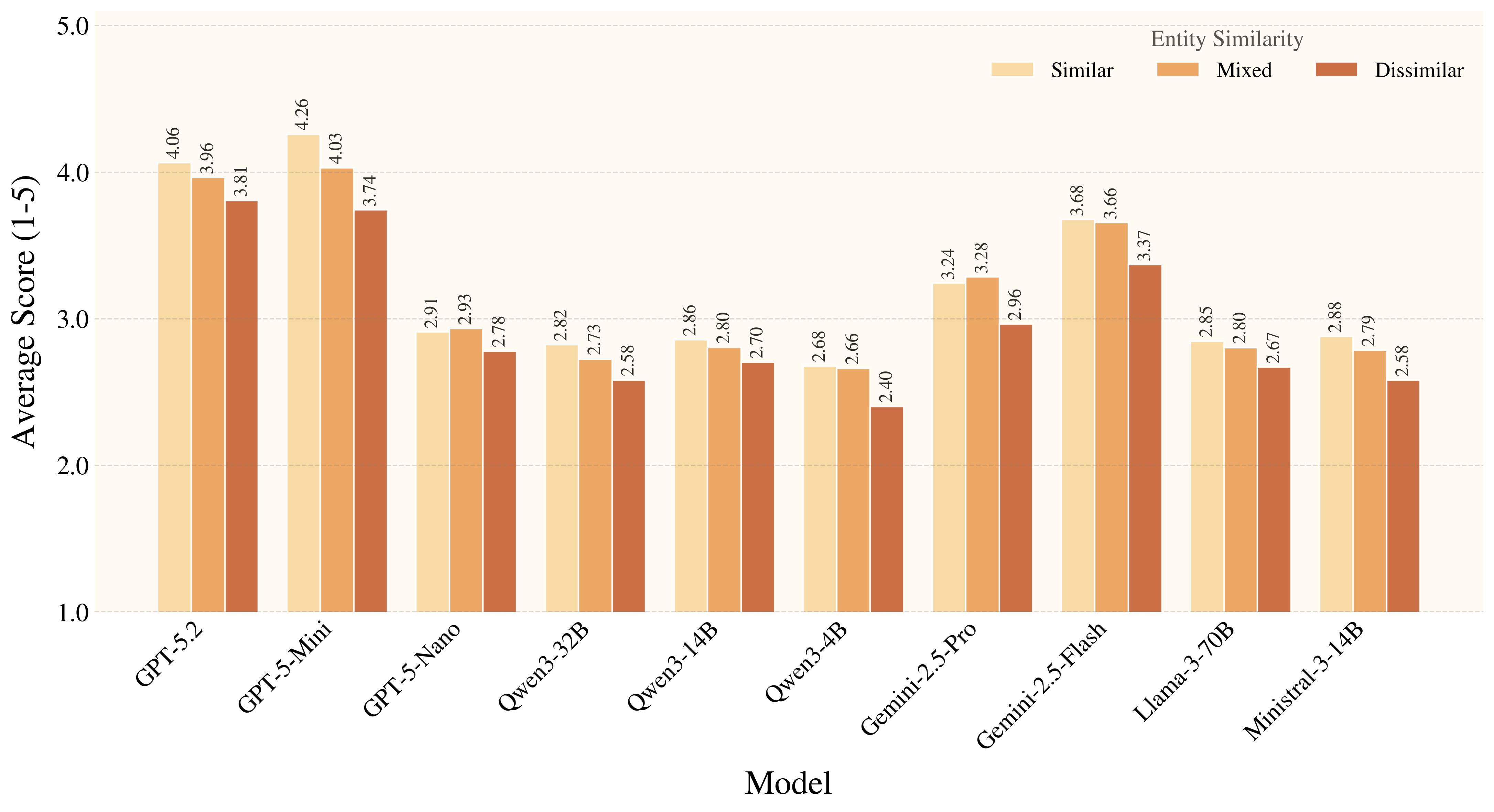
Figure 7. Auxiliary metrics reveal a consistent pattern: models handle familiar affordances much better than rare ones, and they benefit from distractors that provide affordance-level cues. Overall, current models still struggle to ground rare, weakly signaled affordances in a physically and conditionally appropriate way.
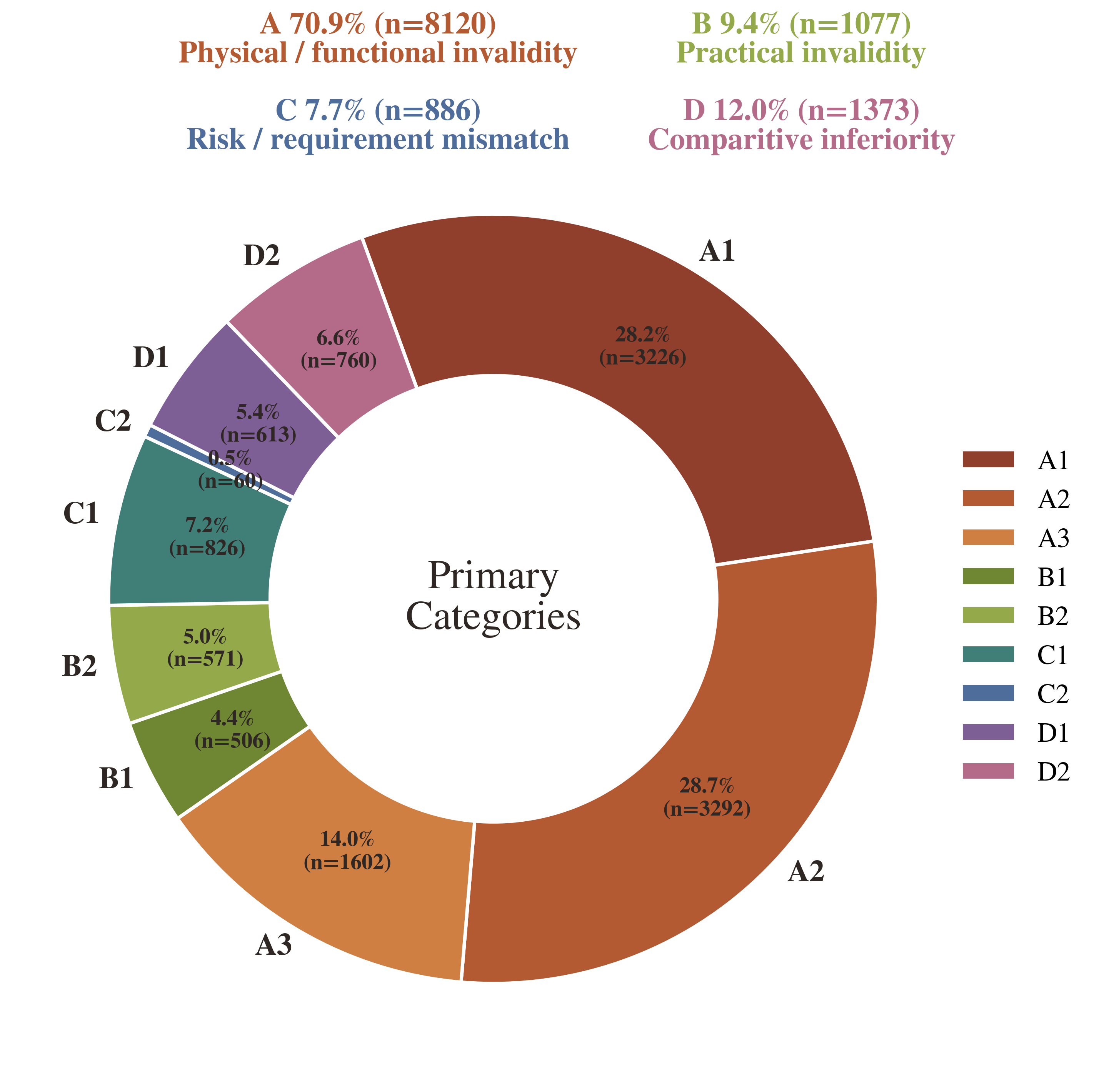
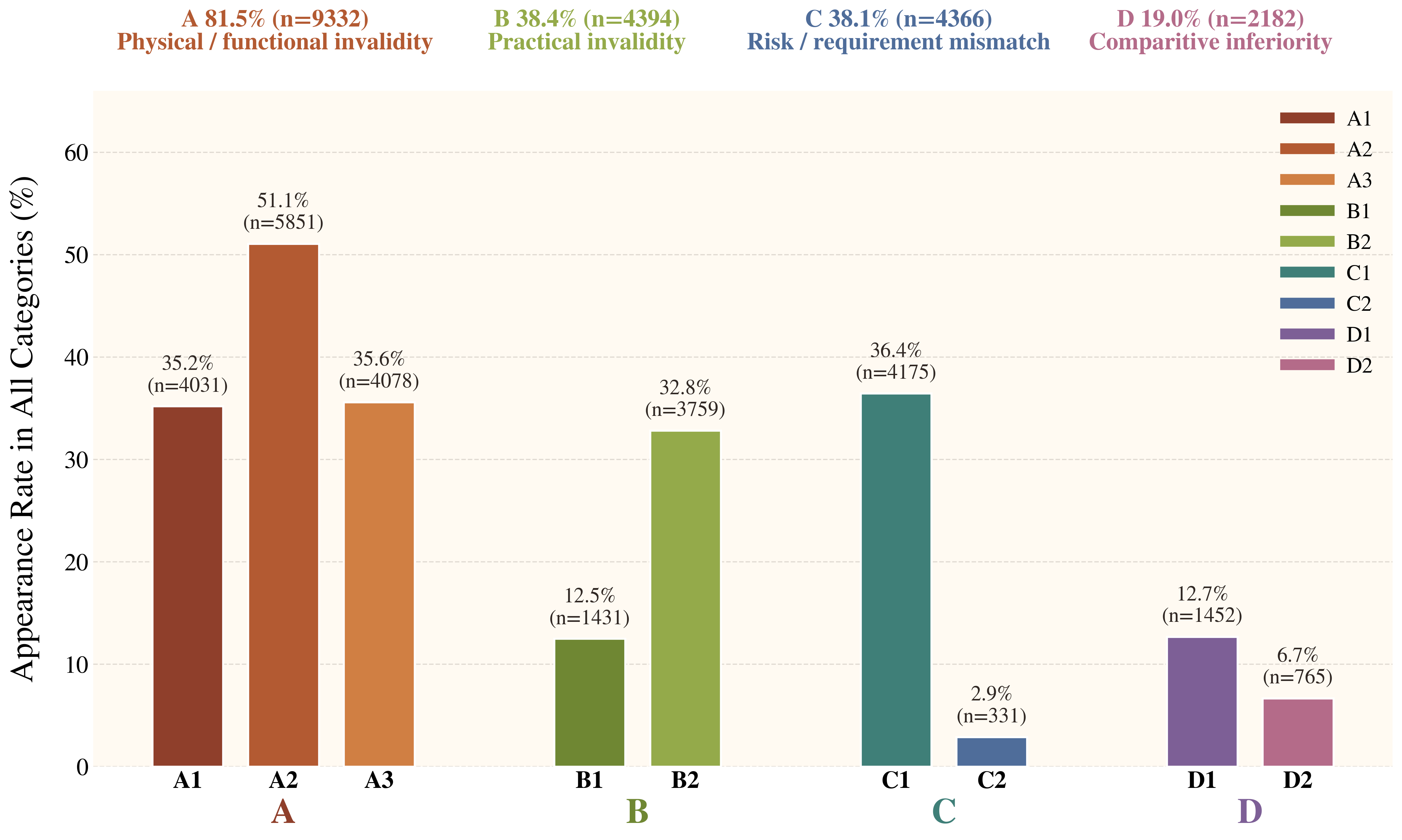
In this section, we conduct an attribution-based error analysis to identify the primary failure modes in creative tool use. For each model, we randomly sample 10% of its failure cases, resulting in a representative set of failed episodes. We then use Gemini-3.1-Flash-Lite as a categorization model to analyze why each prediction is considered inferior to the gold solution. We identify four major categories of errors: physical invalidity, practical infeasibility, risk or constraint mismatch, and comparative inferiority. Each category corresponds to a distinct stage in the affordance-based reasoning process. This categorization enables us to disentangle failures due to incorrect physical reasoning, impractical procedures, constraint violations, and preference-based comparisons, providing a more fine-grained understanding of where current models break down in affordance-based creative reasoning.
@article{qian2026creativitybench,
title={CreativityBench: Evaluating Agent Creative Reasoning via Affordance-Based Tool Repurposing},
author={Qian, Cheng and Ha, Hyeonjeong and Liu, Jiayu and Kim, Jeonghwan and Liu, Jiateng and Li, Bingxuan and Tiwari, Aditi and Dalal, Dwip and Wang, Zhenhailong and Chen, Xiusi and Namazifar, Mahdi and Li, Yunzhu and Ji, Heng},
journal={arXiv preprint arXiv:2605.02910},
year={2026}
}


