 Advancing Creative Physical Intelligence in Large Multimodal Models
Advancing Creative Physical Intelligence in Large Multimodal Models
We introduce MM-CreativityBench, a multimodal benchmark for evaluating whether large multimodal models (LMMs) can perform grounded creative reasoning through affordance-based tool repurposing. While recent advances in LMMs have enabled strong visual understanding and general reasoning capabilities, it remains unclear whether these models can generate novel yet physically plausible solutions grounded in perceptual evidence.
MM-CreativityBench addresses this challenge by focusing on a core component of creative intelligence: the ability to infer how an object’s parts and physical attributes enable unconventional but feasible uses under constraints. Rather than relying on canonical tool usage, the benchmark evaluates whether models can visually inspect environments, identify relevant object parts, and reason about non-obvious affordances to produce constraint-satisfying solutions grounded in physical reality.
Unlike prior creativity benchmarks that are primarily text-centric or scenario-driven, MM-CreativityBench emphasizes visually grounded and evidence-driven reasoning. Each task provides structured multimodal context, including scene images, object-centric views, and fine-grained part-level observations, requiring models to actively connect perception with functional reasoning. The benchmark further evaluates whether models can sustain interactive exploration, avoid hallucinated affordances, and justify solutions using observable evidence.

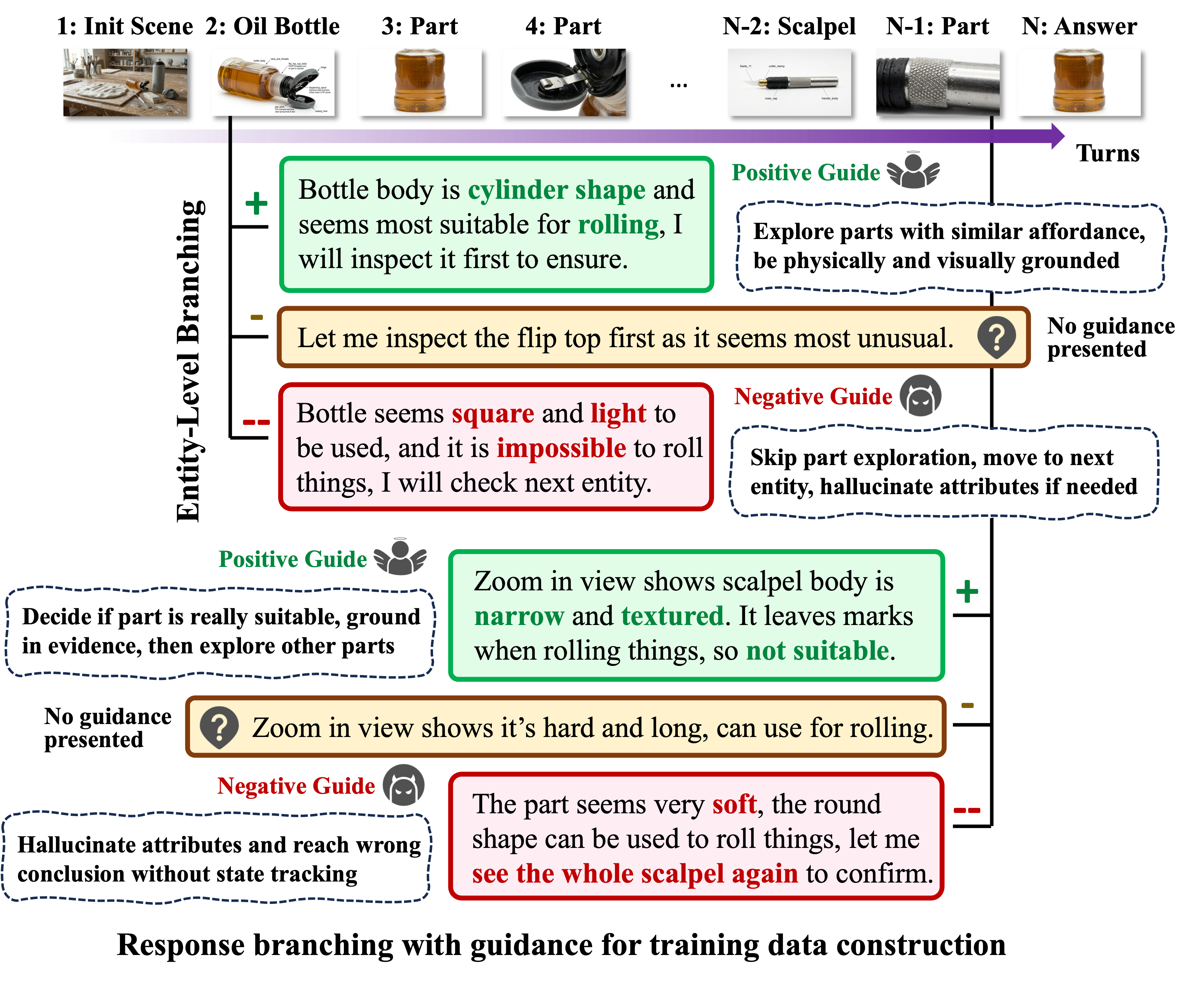
We use the interactive protocol: each example starts with a scenario image containing multiple entities, and the model may inspect entities and parts for closer views before answering.
1. Initialization: Given the scene and task, the model proposes an ordered list of candidate entities to initialize exploration stack, thereby directing early exploration toward likely relevant objects.
2. Inspect Entity: When an entity is inspected, it is removed from the stack, and its affordance-relevant parts are pushed for part-level inspection. This turns coarse entity-level exploration into finer part-level verification.
3. Inspect Part: When a part is inspected, it is removed from the stack and assigned a binary judgment, indicating whether its observed attributes satisfy the task requirements.
4. Answer: Exploration stops when no unexplored entity or part remains. In the final answer turn, the model compares all inspected parts with $b_t=1$ and selects the final pair.
We align the model in two stages: SFT learns structured exploration from positive trajectories, while turn-level DPO improves attribute-affordance grounding by contrasting grounded reasoning with plausible but visually and physically unsupported alternatives.
1. SFT: SFT is executed with positive trajectories sampled, which are guided by structural affordance knowledge base, relevant attributes, and the gold solution. Rather than only final answers, SFT teaches the model to select candidate entities, inspect relevant parts, interpret attributes, and compare entity-part pairs before answering.
2. Turn-Level DPO: To reduce the gap between guided training and unguided inference, we further apply DPO using preference pairs, where preferred trajectories are grounded to attribute-affordance knowledge similar to SFT data while rejected trajectories are sampled by keeping valid action formats and plausible entity-part choices, but misinterpreting or overclaiming visual evidence. Contrasting responses under the same context trains the model to prefer reasoning that justifies affordances with observed physical or state attributes, directly targeting attribute-affordance failures under multimodal uncertainty.
The benchmarking results on MM-CreativityBench. Models often locate the relevant entity but struggle with fine-grained gold-part grounding. Larger exploration traces improve evidence coverage but do not guarantee correct answers, revealing bottlenecks in visual evidence use.
SFT + DPO with hard negatives achieves the highest gold and entity correct rates with more efficient exploration. Gold parts and entities are more frequently explored when the final answer is correct than when it is wrong, suggesting that correct answers are typically grounded in relevant exploration.
Training improves both accuracy and efficiency: SFT organizes exploration, while DPO helps models reject misleading evidence and commit earlier to valid grounding paths.
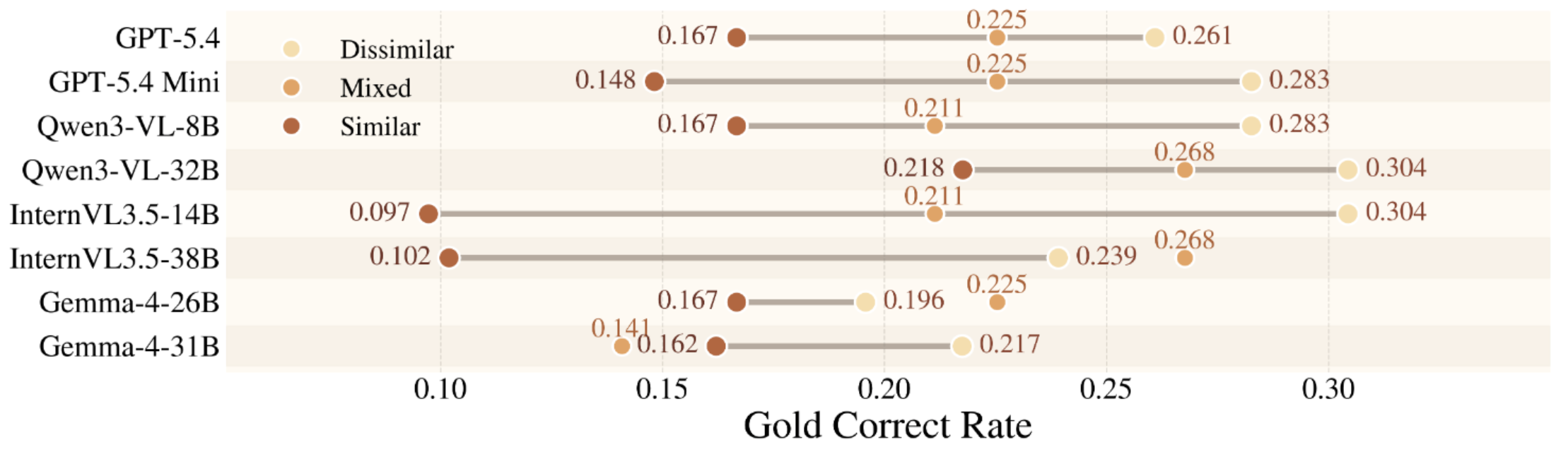

Figure 4. Affordance-similar distractors primarily challenge models at the level of fine-grained visual grounding and affordance disambiguation rather than exploration effort.
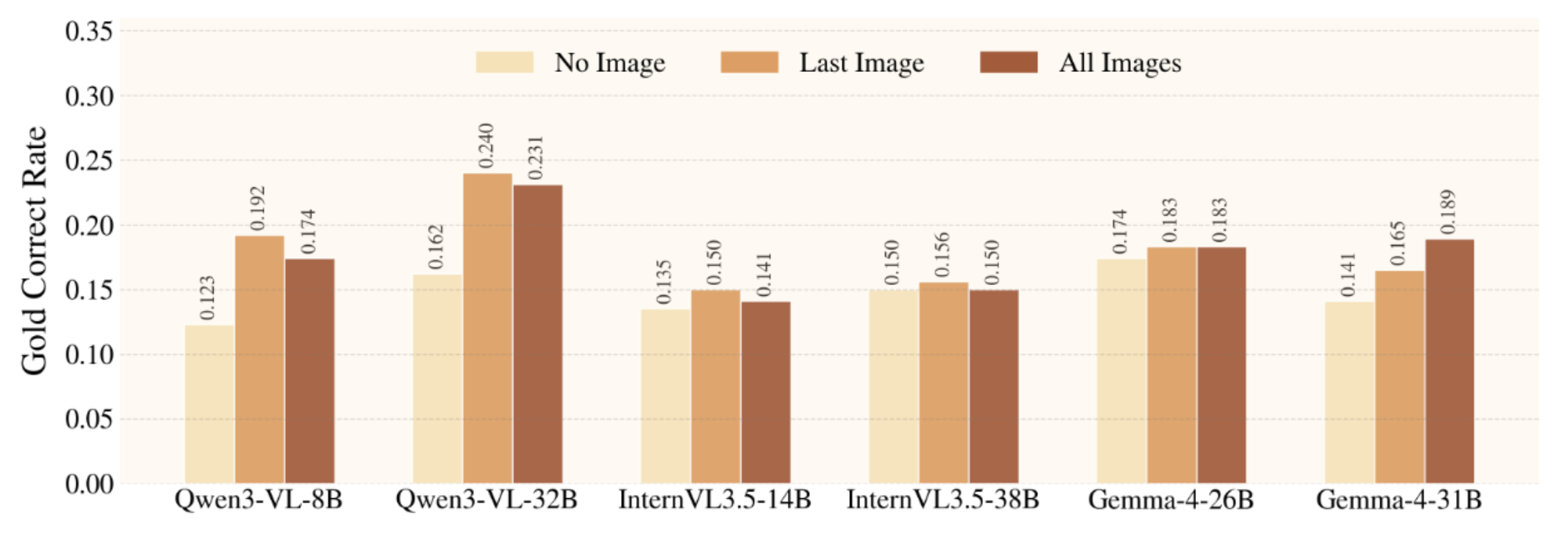
Figure 5. Visual context is necessary for MM-CreativityBench, but performance depends not only on seeing images, but also on iteratively integrating task-relevant visual evidence via interaction.
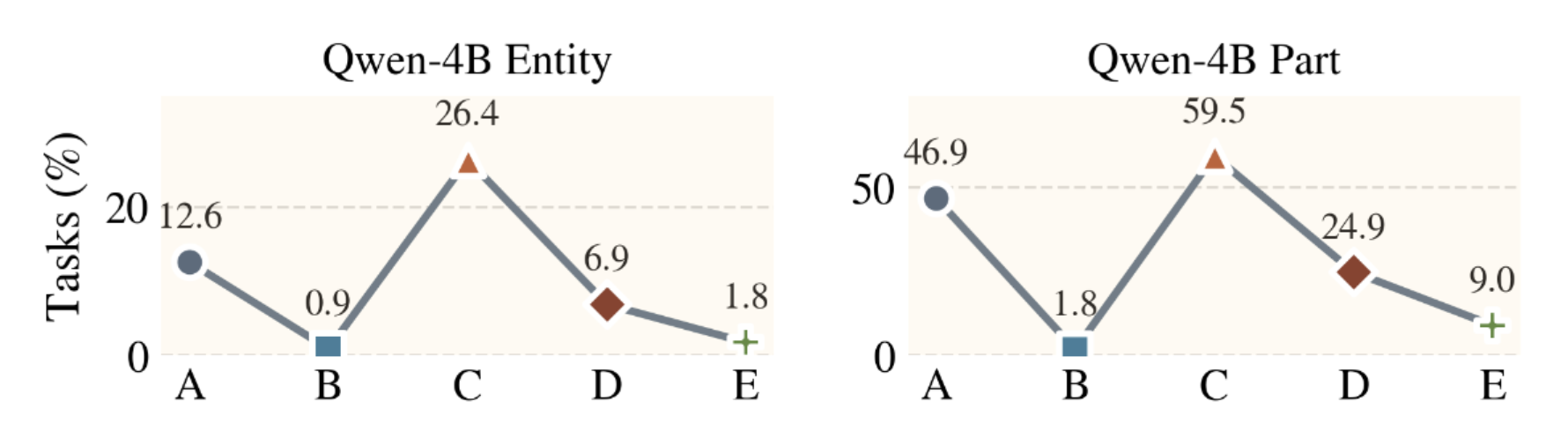
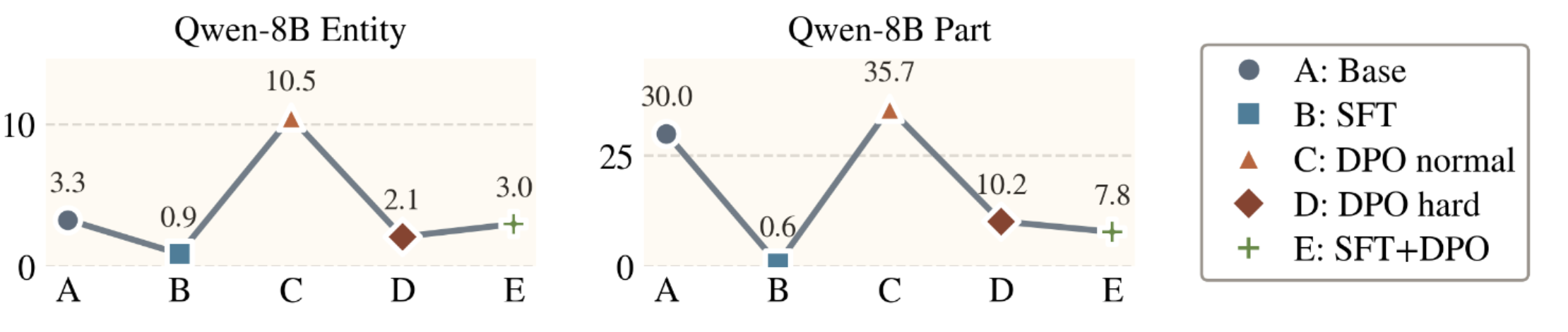
Figure 6. Repetition Rate measures how often the model revisits previously explored entities or parts, where lower values reflect better state tracking efficiency. SFT, DPO with hard negatives, and SFT+DPO all substantially reduce redundant exploration. Our training improves the model’s ability to maintain an exploration state and avoid revisiting already inspected regions.
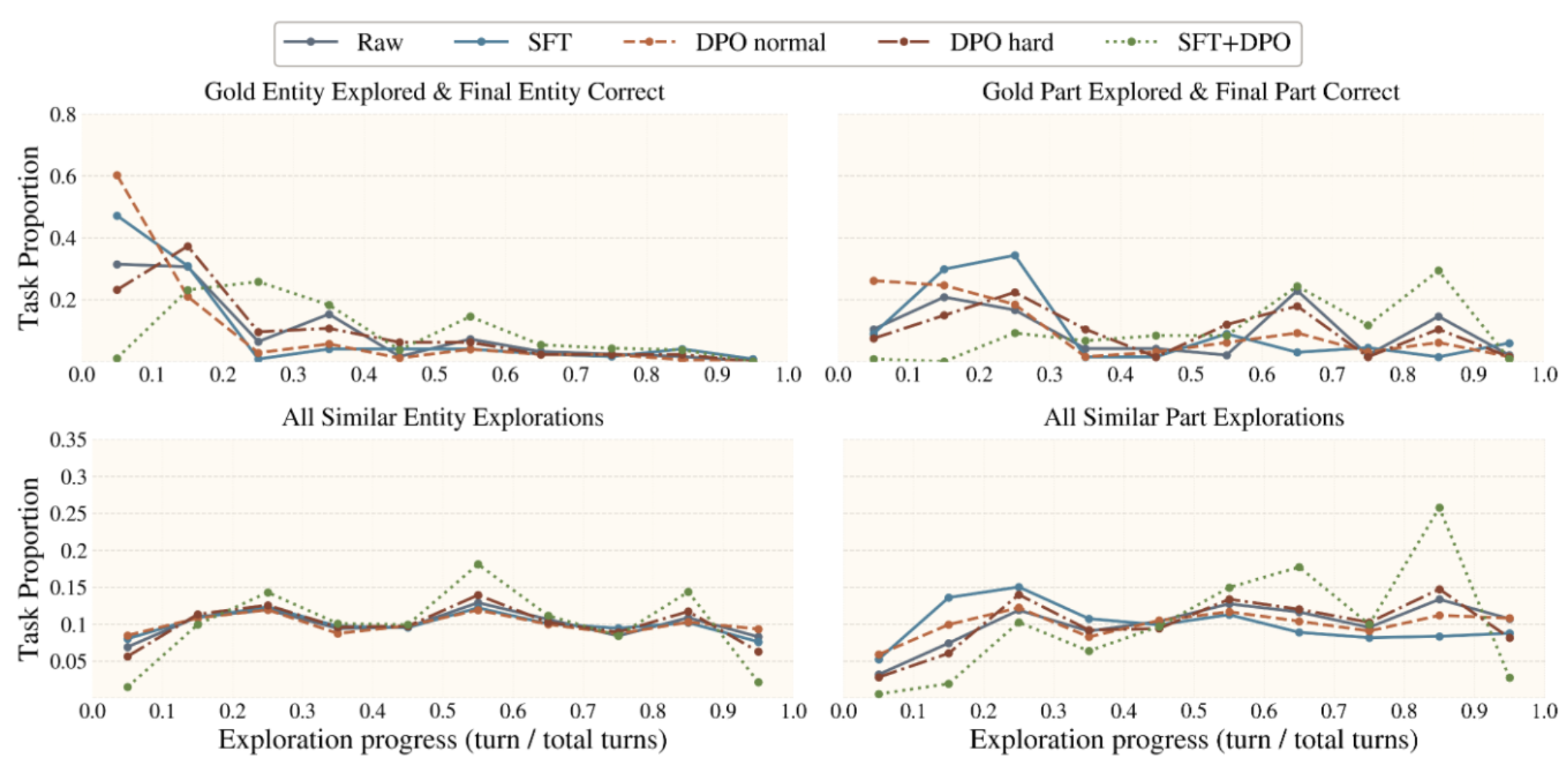
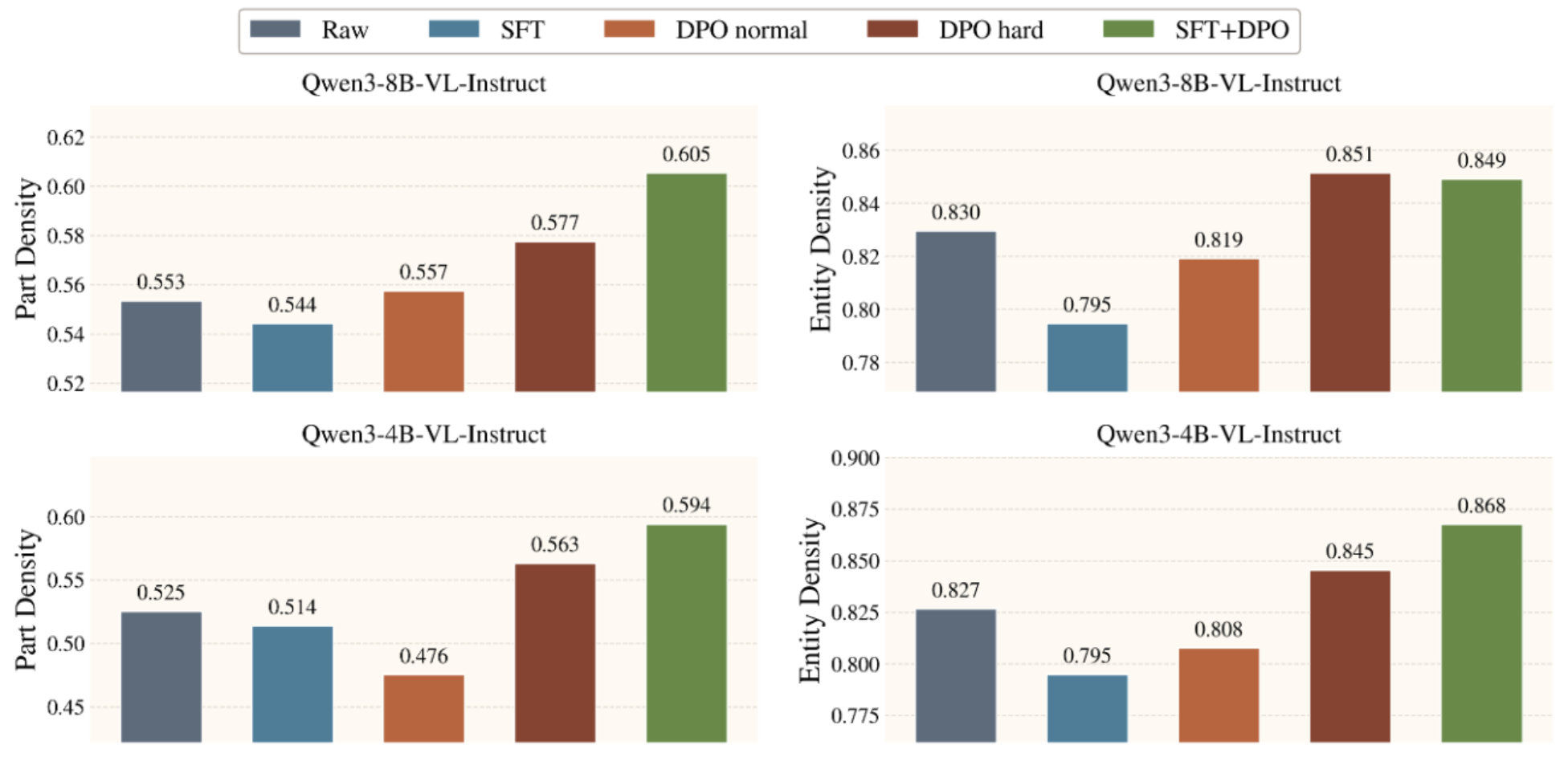
Figure 7.Similarity Density measures how concentrated exploration is around useful hypotheses: part-level density is the fraction of explored parts that are gold part or affordance-similar to it, while entity-level density is the fraction of explored entities that are gold entity or contain at least one affordance-similar part. Exploration Progress records when such candidates are discovered along the trajectory using the normalized turn index.
SFT improves exploration discipline and state tracking, while DPO steers exploration toward semantically useful hypotheses.
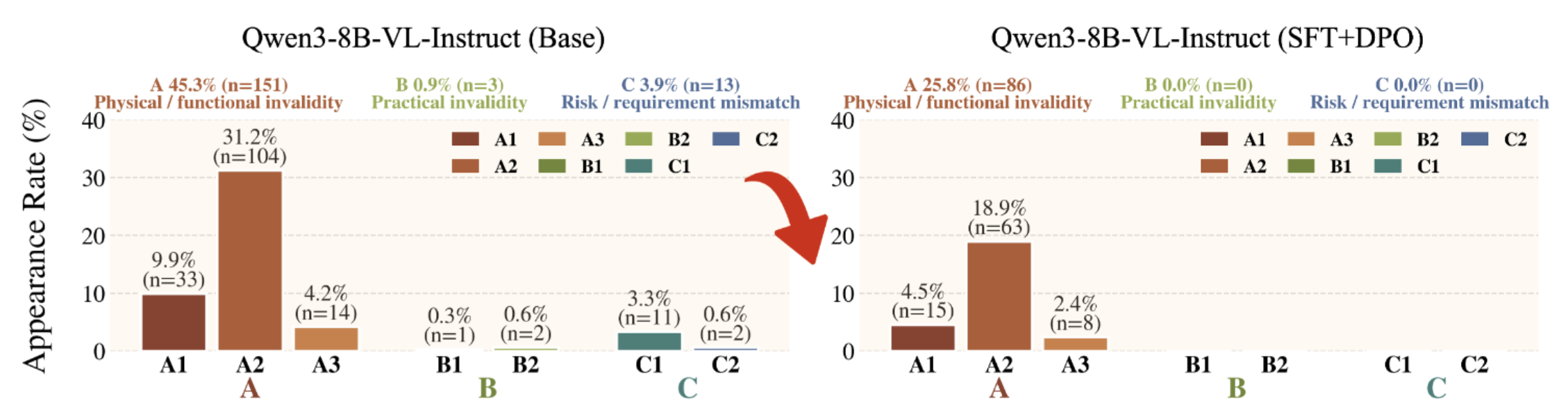
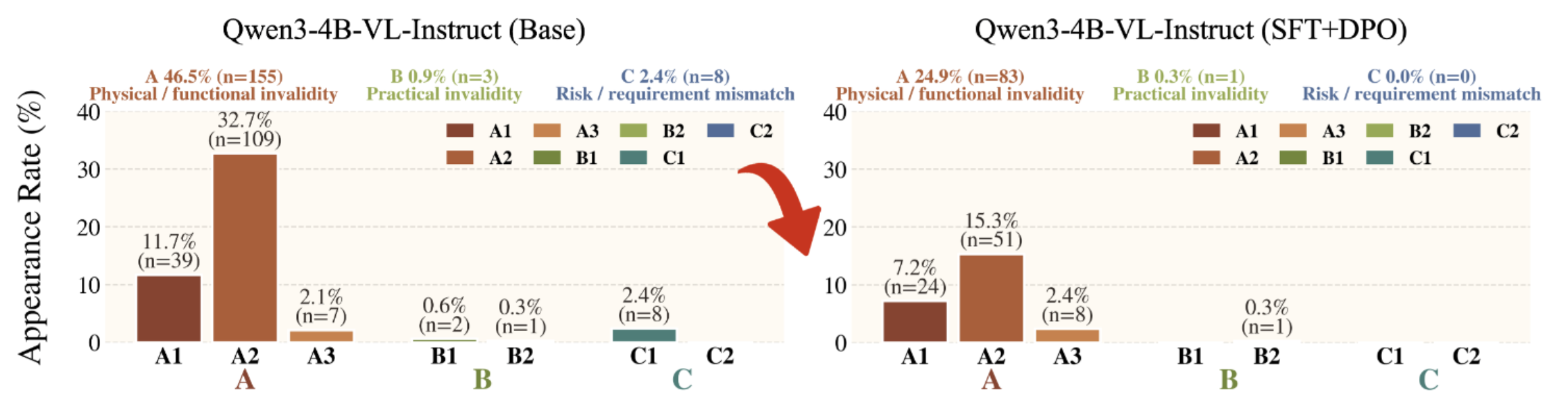
Figure 8. Primary error-category rates reveal that SFT+DPO substantially reduces physical/functional invalidity errors, especially affordance mismatch (A2), and removes most practical and risk/constraint errors.
@article{qian2026advancing,
title={Advancing Creative Physical Intelligence in Large Multimodal Models},
author={Qian, Cheng and Ha, Hyeonjeong and Liu, Jiayu and Kim, Jeonghwan and Acikgoz, Emre Can and Li, Bingxuan and Zhu, Kunlun and Liu, Jiateng and Tiwari, Aditi and Wang, Zhenhailong and Chen, Xiusi and Namazifar, Mahdi and Ji, Heng},
journal={arXiv preprint arXiv:2605.26396},
year={2026}
}

